The lifecycle of a code AI completion
Generative AI, whether for code, text, images, or other use cases, appears as a magic black box to many users. Users typically navigate to a website, install an app, or set up an extension and start seeing the results of the AI tool. But, have you ever wondered what goes into this magic black box or how it really works?
In this post, we want to demystify what goes into a code AI completion for Cody, our code AI assistant that knows your entire codebase. Leveraging a Large Language Model (LLM) to generate a code AI response is fairly trivial, but doing so in a production-grade application that serves many different use cases, coding languages, workflows, and other variables while achieving a high-level of completion acceptance and developer happiness is a whole other thing. We’ll cover the importance of the underlying LLM but also expand the implementation to a fully featured AI engineering system that features various pre and post processing steps, discuss the role of context and how to retrieve it, and more as we explore the lifecycle of a code AI completion. Let’s dive in!
Code completions 101
In its minimal form, a code autocomplete request takes the current code inside the editor and asks an LLM to complete it. You can do this with ChatGPT too! Consider the following example:
// sort.js
function bubbleSort(array) {
|
}
From this limited file we already have a lot of information to work with:
- The cursor is inside the function body so the user is most likely going to continue writing code at this position
- We know that the file is called
sort.js - The code before the cursor (which we refer to as prefix) has strong hints about what code we want to write
- The code after the cursor (postfix) is empty and consists only of a closing bracket.
We can easily convert this into a prompt for ChatGPT and have it generate the implementation for us: https://chat.openai.com/share/27aeb581-2d68-4ac8-94eb-3c64af91f0c6
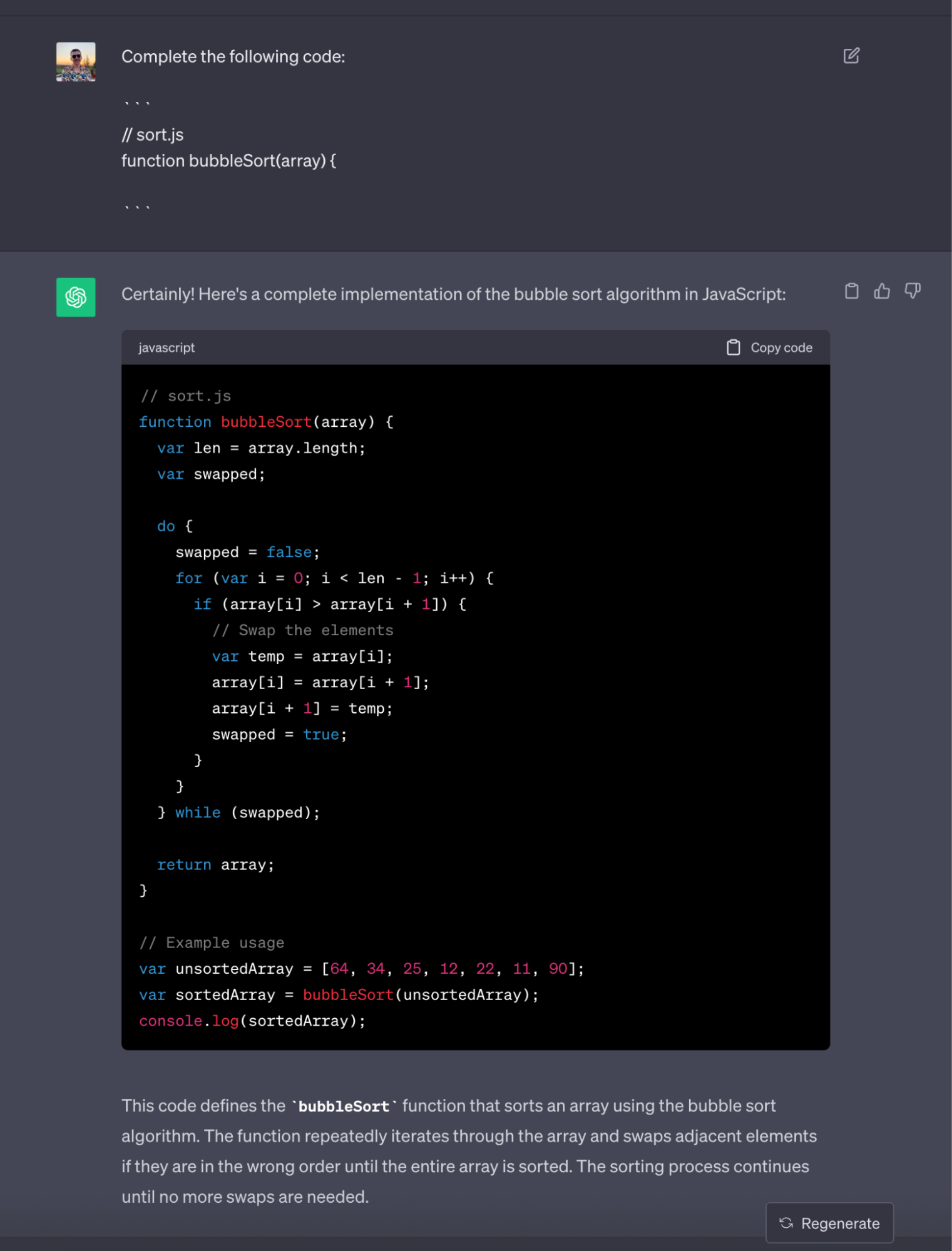
Congratulations, you just wrote a code completion AI!
In fact, this is pretty much how we started out with Cody autocomplete back in March! All you need to make this into a full-blown VS Code extension, is to implement this API interface:
/**
* Provides inline completion items for the given position and document.
* If inline completions are enabled, this method will be called whenever the user stopped typing.
* It will also be called when the user explicitly triggers inline completions or explicitly asks for the next or previous inline completion.
* In that case, all available inline completions should be returned.
* `context.triggerKind` can be used to distinguish between these scenarios.
*
* @param document The document inline completions are requested for.
* @param position The position inline completions are requested for.
* @param context A context object with additional information.
* @param token A cancellation token.
* @return An array of completion items or a thenable that resolves to an array of completion items.
*/
provideInlineCompletionItems(document: TextDocument, position: Position, context: InlineCompletionContext, token: CancellationToken): ProviderResult<InlineCompletionItem[] | InlineCompletionList>;
However, our trivial implementation has a few shortcomings: In a real world application, this would be too slow, it would not have understanding of the right syntactic boundaries, and it would lack contextual awareness of your codebase. The interaction with the LLM is important, but only a small piece of a much larger AI engineering system. Let’s dig a bit deeper and see what it takes to make Cody, a production ready AI application.
How to get great AI completions
Before we dive into the specifics, let’s outline a few basics principles for getting great AI completions. In fact, the principles are the same as if you’re asking someone new on the team to do great work! In order to do their work, the new dev (or the AI assistant) needs to have an understanding of the task at hand. We refer to this knowledge as context. The more context you have, the more effective you’ll be in a project.
For code completions, we can use the current code file as the basis for our context. When writing code, you start by pointing the cursor at a specific position inside the document. From that position, we can define the prefix as the text before and the suffix as the text below that cursor. When coding, your lowest level task is to insert code between the prefix and the suffix.
However, a developer will also look at other files in the project and try to understand relationships between them: Some of this extended context might come from introduction material during their onboarding, their own mental model, existing code and API interfaces, and so much more.
To get great AI completions, we need to think along the same lines and must be able to extract relevant context for the current problem. Modern LLMs already come with a lot of context from the data they were trained on. They know the programming language and are familiar with a lot of the open source libraries that are commonly associated with it. So our task is to fill in the gaps and add context that is specific to the project at hand.
In AI engineering, we call this process RAG (retrieval augmented generation). We retrieve specific knowledge, like code snippets and documentation, from any external knowledge source (which may or may not be included in the model training set) and use it to guide the generative process. If I point you to an arbitrary file in an arbitrary codebase and ask you to “write some code”, you’d also appreciate some context about that codebase. RAG is about automating this process.
When working on code completions inside the editor, we can use APIs available in the editor to get as much context as possible. For example: What repo are you working on? What are other files that you have recently edited? Are you trying to write a docstring, implement a function body, or work out the right arguments for a method call?
With Cody, we use a two step process for retrieving context. We first have a planning step that is packed with heuristics to categorize the type of code completion that is required and then, based on that, retrieve context that works best for the problem at hand.
Once we have a collection of context, we build a prompt that is optimized for the underlying LLM. In our ChatGPT example we would ask it to “complete the following code”. Then it’s up for the GPUs to roll the dice and give you some text back. This step is usually referred to as the generation.
Lastly, we want to do some processing on the generated content. In the ChatGPT example above, there is a lot of text that we do not want in the text editor, for example. We refer to this step as post-processing.
To summarize, every Cody code completion currently goes through these four steps:
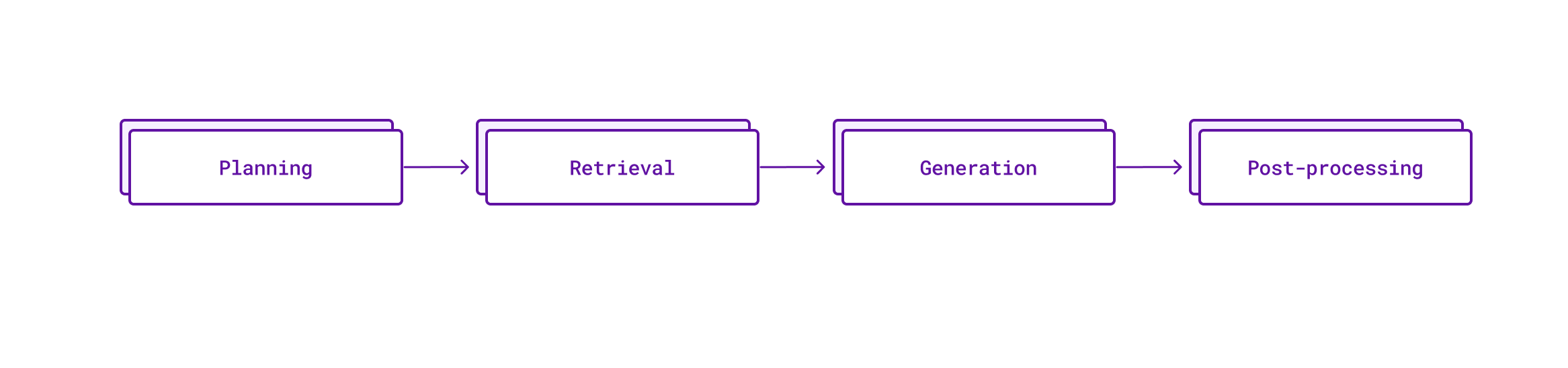
Planning
The first step is all about preparing the best possible execution plan for the autocomplete request. We must decide on what context we believe would work best and what parameters to use for the generation process. At the moment, all of these steps are rule based (that is, they do not invoke any AI system yet and are usually very fast to complete) and based on heuristics that we’ve gathered over time. You can compare this a lot to a database that does a query planning step before it does any of the heavier work. It allows us to divide the problem space into different categories and optimize for them individually, instead of trying to create a one-size-fits-all solution.
Let’s dive into some of the heuristics we currently use in production during this step:
Single-line vs. Multi-line requests

The first learning we had is that there are situations where a user would only expect the current line to be completed and situations where users are willing to wait longer in order to receive a completion that fills out a whole function definition. To detect which type of request is needed, we use a mixture of language heuristics (by looking at indentation and specific symbols) and precise language information (guided by Tree-sitter, more on that later).
Multi-line requests run through the same pipeline but have additional logic during post-processing to make sure the response fits well into the existing document. One interesting learning was that if a user is willing to wait longer for a multi-line request, it usually is worth it to increase latency slightly in favor of quality. For our production setup this means we use a more complex language model for multi-line completions than we do for single-line completions.
Because of the language-specific nature of this heuristic, we generally do not support multi-line completions for all languages. However, we’re always happy to extend our list of supported languages and, since Cody is open-source, you can also contribute and improve the list.
Syntactic triggers
The position of the cursor relative to elements of code like the beginning of an expression or the current block scope offers insight into the user's intent and desired completion behavior. The first version of Cody used regular expressions to approximate these syntactic clues, but there is only so much information that you can extract from plaintext pattern matching. The current version of Cody uses a great tool to obtain concrete syntax trees for each file: Tree-sitter.
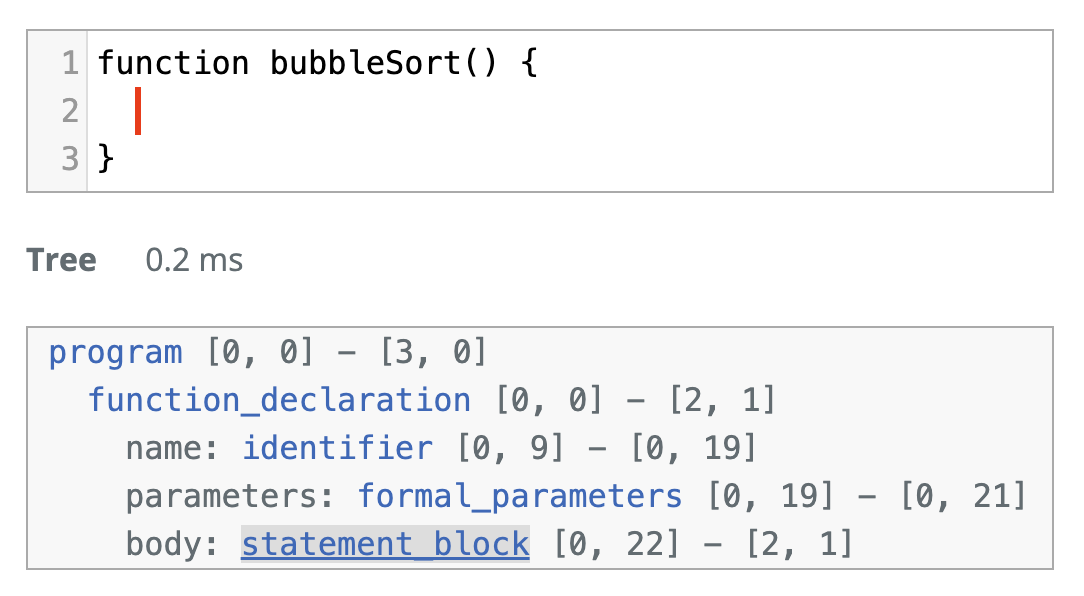
At Sourcegraph, we are long-time users of Tree-sitter for improving our code search experience and it felt natural to extend the usage for our autocomplete pipeline. More specifically we use custom-built WASM bindings to parse the current document state and use that to trigger syntax-specific branches–For example, to detect if the cursor is currently within a comment.
Tree-sitter is great for this use case because it is extremely fast, supports incremental parsing (so after a document is parsed, changes can be applied with very low latency) and it’s robustness allows us to use it even when the document is currently being worked on and contains syntax errors.
During the planning step, we use Tree-sitter to categorize the autocomplete request into different syntactic actions like implementing a function body, writing a docstring, or implementing a method call. We can then use this information to focus on different types of contexts or modify the parameters for the generation phase.
Suggestion widget interaction
If you’ve worked with VS Code you’re probably familiar with the suggestion widget. It pops up when you’re trying to call a method on a class and will list you all of the methods that the class implements and is powered by the mighty IntelliSense system. In the context of autocomplete, VS Code gives us some hints to create better interoperability between AI suggestions and the suggest widget as part of the InlineCompletionContext, the range of the document that is going to be replaced with the suggestion and the currently selected suggestion.
Using the suggest widget to steer the LLM results is absolutely magical:
Retrieval
Depending on the model being used, there are varying limitations for how long such a context window can be but regardless of these limitations, finding the right code examples and prompting them in the correct way will have a huge impact on the quality of the autocomplete result, as outlined above.
One of the biggest constraints on the retrieval implementation is latency: Retrieval happens before any of the generation work can start and is thus in the hot path of the life cycle. We generally want the end to end latency (that is, the time between the keystroke and the autocomplete becoming visible) to be as fast as possible, definitely under one second and since this must account for network latency and inference speed, there’s not a lot of room for expensive retrieval.
From the first version on, Cody’s main retrieval mechanism was to look at editor context. This takes into account other tabs you have open or files that you recently looked at. The result of such retrieval processes are a few example code snippets that are sorted by relevance. We currently use a sliding window Jaccard similarity search to do that: We take a few lines above the current cursor position as the “reference” and then start a sliding window over relevant files to find the best possible matches.
In order to reduce client CPU pressure, we limit the files to the most relevant ones. These are usually the files you looked at very recently and are generally written in the same programming language.

Over the past few months we’ve experimented with various other context improvements. One thing that seemed very promising was to reuse our existing embeddings index that we already use for other Cody features. We’ve started to move away from this approach as we’re working on improving the accuracy of embeddings responses and removing the need to do extensive caching to make this work.
Editor context is only one possible source for information though and having one of the world’s largest code graphs, there’s a lot more that we can do. One overarching problem that we’re working on right now is how do we rank information from different sources and only include the relevant information (we have learned from internal experimentation that adding irrelevant context can make the response quality worse).
Generation
As we move to the next stage, let’s dive into the heart of the autocomplete process: the Large Language Model (LLM). The LLM is responsible for taking the prompt and generating a completion that is relevant, accurate, and fast.
Sourcegraph has been a vivid early adopter of Anthropic’s Claude. Because of this, our Autocomplete journey started with early experiments in prompting Claude Instant (for its faster response times) to create code completions similar to the ChatGPT example we explored above. We quickly learned that a simple prompt resulted in a lot of frustration for our users:
- No Fill in the Middle support: Without adding information from the document suffix, the LLM would often repeat code that is already in the next line. In the terminology of LLMs, this use case is often described as fill in the middle (FITM) or infilling, as the problem is to insert text in the middle of existing text.
- Latency: We measured that a significant number of requests came back with no response at all (so the LLM decided to terminate the request early).
- Quality: Slight variants in the prompt could have a huge impact on quality. E.g. When we ran an experiment with a prompt that tried to improve the accuracy of comments, we learned that mentioning the term comment caused an increase in comments being generated rather than actual code.
Over the past months, we have made a lot of improvements to the Claude Instant prompt, let me highlight some in particular:
-
The first major update to the prompt changed three things which caused the quality, and more specifically the number of no responses to improve dramatically:
-
We moved from markdown backtick tags for code segments to XML tags as suggested by Anthropic. Since Claude has been fine tuned to pay special attention to the structure created by XML tags, we found an improvement in response quality with this easy change. It pays off to read the docs!
-
We found that including whitespace at the end of the prompt would cause significantly worse responses. In the
bubbleSortexample above, we would end the prompt in all of the whitespace that lead to the cursor so it would end in\nfollowed by four spaces. In real world applications, the indentation would often be higher resulting in even more whitespace. We achieved a significant reduction of empty responses by trimming the prompt and accounting for the whitespace differences in post-processing. -
We also started to lay words in Claude’s mouth by omitting information in the initial question and then leading with this in the assistant prompt. An example for this could be a completion for these two lines:
const array = [1, 2, 3]; console.log(|Which would translate into a prompt like this:
Human: Complete the following code <code> const array = [1, 2, 3]; </code> Assistant: Sure! Here is the completion: <code> console.log(
-
-
The second major update was to add support for Fill in the Middle: Instead of only quoting the prefix, we also added information about the code after the cursor into the prompt. This was not trivial since simple implementations often caused the LLM to simply repeat from the suffix without generating new code. We ended up using a combination of XML tags and the extended reasoning capabilities of Claude Instant 1.2 to our advantage here.
The strive for faster latencies
A general purpose model like Claude Instant is great as it allows you to extend the capabilities of the system by writing better instructions. There is, however, a catch: These advanced reasoning capabilities require a much larger model to work and as a result, end-to-end latencies (as measured from the keystroke until the completion is visible) have not been great which significantly impacted the UX of our service. This was also reflected in a lot of early adopter feedback so it’s become an obsession for us to try and improve the status quo.
Latencies apply throughout every step in the autocomplete lifecycle but the generation part is the definitely the slowest since it also requires routing a request to the backend and the LLM provider. In our quest to improve the UX, we had to be pedantic about every step in this process. This, of course, meant that we had to add tracing to every step in the pipeline and then critically think about how we can improve all of these segments. Oh and what interesting things you’ll find when you do that!
Here’s a number of improvements that we applied in order to reduce 75th percentile of end-to-end latencies for single line completion from 1.8 seconds to under 900 milliseconds over the past months:
-
Token limits and stop words: The most time in our request was spent waiting for the LLM to respond (that's somewhat expected). The number of tokens in the prompt and in the output makes a huge difference in these delays, though. After some tweaking and especially the addition of stop-words, we were able to speed up inference times by a ton.
-
Streaming: Later, we'd even start to use streaming (so the LLM can return the response token-by-token) and our client could implement more advanced mechanisms to terminate a completion request early.
For example if you are looking to complete a function definition and the LLM response starts to define another function after the current one is finished, chances are you don't even want to show the second function--So why block the response until the request is finished?
-
TCP connection reusing: Autocomplete requires a lot of requests. Roughly a request for every few keystrokes. We don't think about this often, but every new request requires a handshake between the client and server which adds latency.
Luckily there is a solution here and that is to keep the TCP connection open. What we didn't know: Different HTTP clients have different defaults here and since a Cody autocomplete request is routed from the Client to the Sourcegraph server and then the LLM, we needed to make sure that TCP connections are reused for every step in this pipeline.
-
Backend improvements: The story wouldn't be complete with a few obvious improvements. Once we found out that our logging on the Sourcegraph server does a synchronous write to BigQuery for example, it didn't take long for us to notice that this is probably not the best way. Safe to say our server side logging steps are now no longer blocking the critical paths. Whoops!
-
Parallel request limits: Early on, Cody autocomplete was triggering multiple generations for every request. This was added in order to mitigate shortcomings of the initial prompts: If we have a sample of two or three completions to use, we can improve the quality by picking the best one. The catch for this though: The latency is now defined as the longest duration of any of the three requests. We were able to reduce this level and currently only request multiple variants for multi-line completions (which are generally more error prone and less latency sensitive).
-
Recycling prior completion requests: This is a client level improvement that was able to improve latencies in some cases quite dramatically. Imagine you're trying to write
console.log(. However, while typing, you make a short break between theconsole.and thelog(. This happens all the time as devs think about how to proceed.The small delay would cause Cody to make an autocomplete request, however if you're quick in resuming the typing, that result might not make it to the screen yet as the document state keeps changing.
However, chances are that the initial request (the one with
console.) would already be enough information for the LLM to generate the desired completion. In practice we have measured this to be the case in quite a few cases (about every tenth request). We have added additional bookkeeping to the clients to detect these cases and recycle such prior completion requests. -
Following up on downstream performance regressions: Our extensive latency logging setup was also helpful when the downstream inference provider introduced latency regressions. We're proud of our collaboration with Anthropic on these and the data we could share with them was always helpful to fix the regression quickly.
This is not the end of the journey though and we know there’s still a lot of room for improvement left on the table. One limitation right now is that our backends (the Sourcegraph server and the inference endpoint) are only hosted in one region which is not ideal for users of other parts of the world. There’s also the possibility to improve the raw inference speed, especially as new hardware and algorithms become available.
A use-case specific LLM
Regardless of how fast we make our Claude Instant implementation, we still have to deal with the fact that it's a general purpose model and is thus a lot larger than it needs to be. To avoid falling into a local maxima, we started evaluations of use-case specific LLMs that are only helpful for generating code. Our hypothesis was that:
-
Use-case specific LLMs can be better at the their trained use case while having a reduced size (so they are faster to run)
-
We can take advantage of state-of-the-art models that are trained specifically for the Fill in the Middle use case to further improve our response quality.
-
Tokenization for a coder model is likely going to be in our favor more which means we will be able to generate more characters using smaller token counts.
-
Being able to leverage open source LLMs is going to help us futureproof the system while allowing us to have more control over the deployment (if we want to spin up an inference end point at a specific location, we'll need to be in control of this).
StarCoder has always been a model that we found particularly interesting given that it is built especially for our use case, it has multiple variants (based on the parameters size) so we can run faster models for use cases where we do not need the full accuracy. We can even rely on quantized versions (the name of a technique to reduce the precision of a model to reduce its size), that have almost no visible quality difference while being even faster to run.
After a long evaluation period against other models, we began a broad A/B test on our community user group and, after a few bug fixes and improvements, have recently finished the rollout for community users to this model, resulting in much reduced latencies and an increase in acceptance rate for our users.
At Sourcegraph, we've always believed that our strength does not come from being tied and hyper-optimized around a specific LLM (heck, the one that you optimize for can be outdated in months anyways!) but that we need to be flexible to use the best tooling available and feed it the most relevant context. This unlocks quite a few opportunities where we can easily move to a better model for our users and even support local-only inference with tools like Ollama. After all, the AI journey has only just started!
Post-processing
Once we have a string from the backend we're done, ...right? Well, almost. The reality is that sometimes responses aren't quite what you expect them to be but since we've gone through all of this effort to create these strings, we'll go to lengths to salvage whatever we got back.
With Cody, this step is called post-processing and we employ a number of tricks to make sure the text that is being displayed at the screen is as relevant as possible:
-
Avoiding repeated content: If there's one quality that LLMs have it's that they're really good at repeating content. Unfortunately this sometimes leads to undesired results when the completion contains a line that was already written above or below the cursor. There's only so much we can do with instruction tuning to avoid this so we're also employing rule based systems to guard against this failure case (via algorithms like Levenshtein edit distances).
-
Truncating multi-line completions: Ever since the first implementation of multi-line completions, we identified the need to have language specific rules to know 1) when to trigger a multi-line completion and 2) when to cut it off.
LLMs are really good at continuing to produce output so when you ask it to fill out a function body, chances are that the LLM continues to implement another function and another function and another.... 🙃
To prevent this from happening, we use a combination of two techniques to find out exactly when we want to truncate the completion:
-
Indentation based: The idea for indentation based systems is to leverage code indentations to find out when the response leaves the current indentation level. The handy bit about this is that it's mostly language-agnostic, we only need to handle a few special cases like closing brackets to get usable results.
-
Syntactical: I've already touched on our use of Tree-sitter above but this is another problem area where syntactic knowledge of the code provides us with a great opportunity. Insteading having to guess where a block ends, Tree-sitter can be used to be precise about it. We've seen great improvements in truncation quality by moving to this approach and will likely extend this to support more programming languages in the near future.
-
-
Estimating the relevance of a completion: Once we have a completion, it is handy to be able to score how relevant it is. We employ techniques for this mostly for multi-line completions at the moment (where we have more than one candidate completion available during post-processing and can use this information to select the most probable):
-
Using syntactic parsing: Leveraging Tree-sitter again, we can automatically devalue completions with syntax errors.
-
Using probabilities returned by the LLM: One additional benefit of moving away from Claude Instant is that we now have access to the underlying probabilities that the LLM used to generate the completion. We can sum up probabilities to understand how certain the model is about a specific generation.
-
-
Filtering out obvious bad suggestions: While this is not as big of a problem anymore than it was in our early days, we also have a regex that highlights obvious bad completions. One such example is that in our initial Claude prompt, we'd sometimes get git diff style patches back.
One overarching learning from this step is that we do not want to filter out too many completions. If we err on the side of not showing completions, our users have given us the feedback that the product does not work and it's really unclear for a user as to why. Hence, it's better to focus on generating relevant completions.
Data, data, data…
At Sourcegraph, we’re strong believers in the saying that “If you cannot measure it, you can't improve it” and as a result of this, analytics has always played a key role in how we improve Cody autocomplete. Over time, this system has become quite advanced as there’s a ton of additional bookkeeping needed to account for all of the VS Code APIs oddities and growing demands. Let’s dive into some specifics.
What metrics do we track?
-
Suggestions: At the heard of our telemetry is an event for every completion that was suggested to a user
-
This includes the number of lines and characters of that completion in addition to the execution plan so we know what's being suggested. We also attach latency information and other debugging information to this event.
-
Every completion has a unique UUID so we can combine various data sources to get a more complete picture of the completion.
-
Knowing when VS Code decides to show a completion is unfortunately a hard problem (that is, unless you are GitHub and can implement specific VS Code APIs that no one else can use in production). So in order to understand when VS Code is deciding to show a completion we have a user-space implementation of their display criteria. Even then, another completion provider could be fast to respond to a completion, in which case we don't know if theirs or our completion is shown. We try to guard against this by logging if the user also has one of a list of known completion extensions enabled for their VS Code instance.
-
We also measure for how long a completion was visible on screen. This, however, is not precise as there are also no VS Code APIs so we approximate this based on a few VS Code specific heuristics.
-
-
Acceptances: A straightforward success criteria: If a user uses tab to insert a completion, this is a strong signal that a completion is indeed helpful.
-
Partial acceptances: VS Code specifically has UI to only accept one word or one line from a completion. For a partial acceptance we also log how much (in number of characters) of the completion was added and we only log a partial acceptance when at least one full word of the completion was inserted.
-
Completion retention: To better understand how useful the completions are, we also track how completions were changed over time after they were inserted. For this, we have bookkeeping that detects document changes to update the initial range that a completion was inserted at and then uses Levenshtein edit distances at specific polling intervals to capture how much of the initial completion is still present.
Based on these events, we can compute our most important metric and that is completion acceptance rate. A metric that combines a lot of criteria like latency and quality into a single number.
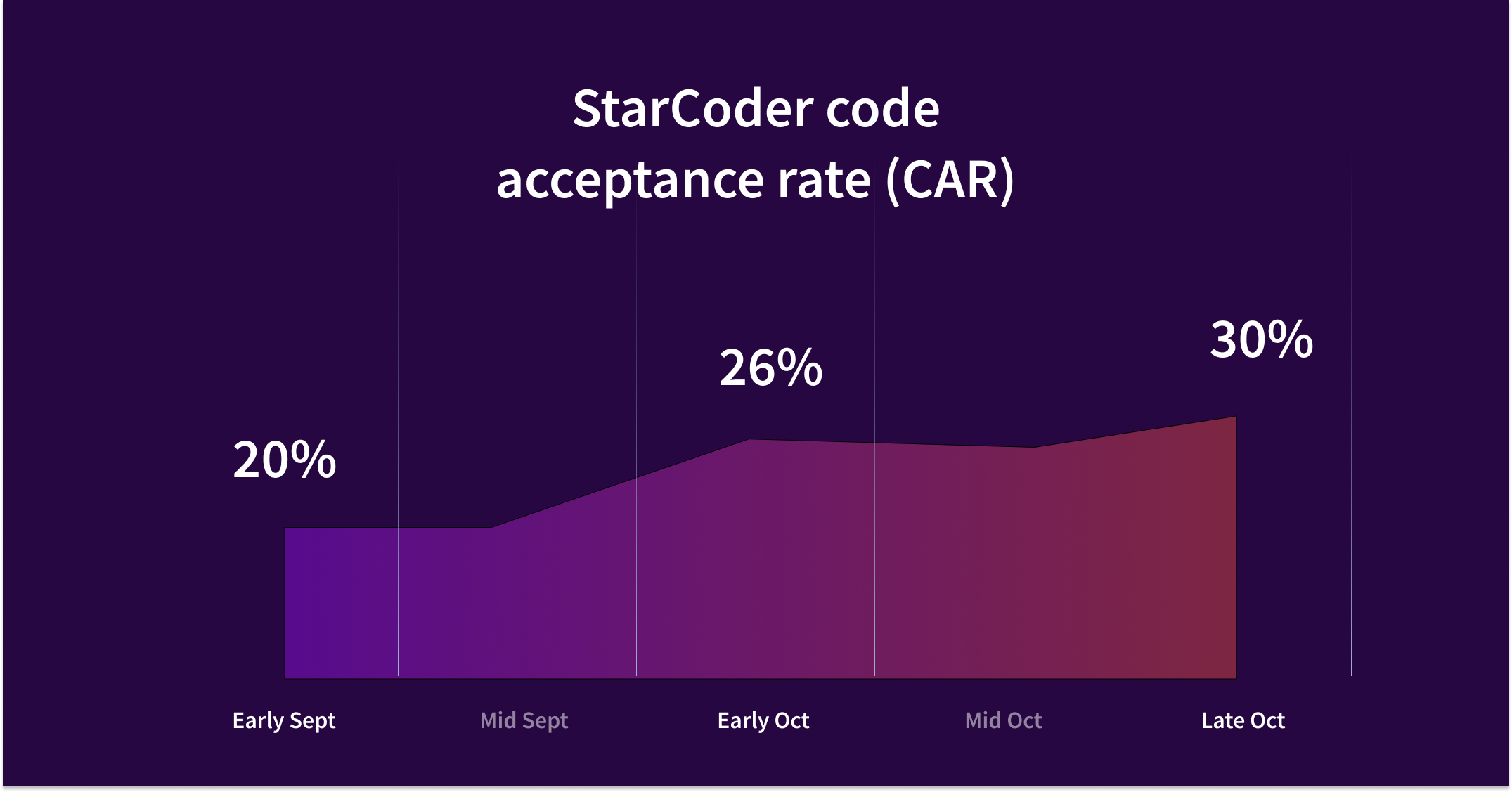
The good news is that our users use Cody autocomplete a lot and that we can use this telemetry to get rapid feedback for improvements and use that to run A/B tests. To showcase how sensitive our logging is: We noticed a 50ms regression to latency in only a few hours of logging. In fact our logging was so advanced that we were able to provide valuable insight and fix performance regressions caused by Anthropic for a while.
By adding a lot of metadata from the previous steps to every autocomplete event, we're able to categorize requests into areas that work well and areas that need more improvement. The combination of Tree-sitter syntax information has been really helpful to identify issues in this category.
One such example is to reduce the frequency of completions on positions where we know that they are unhelpful. One example is if you're at the end of a line but the statement on that line is already complete:
console.log();|
// ^ showing an autocomplete at this point is likely not very useful 😅
Reliability
There is one area that, in my opinion, is often overlooked in software development: Reliability. More specifically, we need to ensure that our system not only works on paper, but that it also does not regress in functionality over time (this can happen by us pushing faulty updates or by the infrastructure failing us in production).
There are a few basics for reliability like unit testing and tracking production errors that every project should implement. Since we’re working with a very flaky environment though (the LLMs indeterministic nature), we’ve had to add a lot more safeguards though.
Autocomplete tests
I won’t go into detail about this and I don’t think this is controversial anymore but automating your tests allows you to move faster. Most of the day to day improvements on heuristics outlined above rely on a large integration test suite that calls directly into the provideInlineCompletionItems API that VSCode uses. By running through the whole autocomplete architecture, we can write tests by defining a document and potential LLM responses and make assertions on all steps along the way. Here’s an example of such a test:
it('properly truncates multi-line responses for python', async () => {
const items = await getInlineCompletionsInsertText(
params(
dedent`
for i in range(11):
if i % 2 == 0:
█
`,
[
completion`
├print(i)
elif i % 3 == 0:
print(f"Multiple of 3: {i}")
else:
print(f"ODD {i}")
for i in range(12):
print("unrelated")┤`,
],
{
languageId: 'python',
}
)
)
expect(items[0]).toMatchInlineSnapshot(`
"print(i)
elif i % 3 == 0:
print(f\\"Multiple of 3: {i}\\")
else:
print(f\\"ODD {i}\\")"
`)
})
In addition to a broad suite of integration tests, we also have E2E tests for our VS Code extensions that fires up a headless version of VS Code and instruments it via Playwright to ensure it’s working properly.
LLM inference test suite
So we know that our implementation works for statically defined LLM responses. But how do we evaluate that changes we make actually have a positive impact on the overall user experience? One way of thinking about this is by looking at your production metric, but even in scenarios where you have lots of data, this usually results in a slow feedback cycle since you need to push a change, run an experiment and wait for it to conclude, evaluate it, and start again…
To improve our feedback cycles, we started very early to collect static examples of specific document states to automatically run our whole autocomplete stack against it. These only consisted of prefix and suffix pairs and were mostly evaluated manually using a small web UI that we built. It’s been super helpful to hook up new models, work on prompt changes, and tweak the generation parameters.
Over time, the manual evaluation became more and more work as we’ve added more examples and focusing only on one file was not a good replication of how a user works in their IDE. Testing LLMs created for code generation is a known problem and so we looked at existing solutions like the famous HumanEval tests. Those tests are usually also constrained to a single input file but they do have tests associated that can be run to validate the solution for correctness. These tests are great to validate the underlying LLM but they still do not capture the big picture of a user using their IDE to write code.
We knew we had to do more to build the best autocomplete experience and so we’ve recently overhauled our LLM inference test suite to document more and more cases of how code completion is used in the editor. Examples that encapsulate a whole workspace configuration like when you are writing a class, and then move to a different file and try to write a unit test for this class. We also added a system to run automated tests against the generated completion to measure its correctness. This allows us to test changes across the whole autocomplete stack quickly and without the need to deploy them, and get a sense of whether they improve the experience or not… And it’s only the beginning!
Summary
In this post we looked at the lifecycle of a code AI completion for Cody. To summarize, every Cody completion goes through four steps:
-
Planning - analyzing the code context to determine the best approach for generating completions, such as using single vs. multi-line completions.
-
Retrieval - finding relevant code examples from the codebase to provide the best possible context for the LLM.
-
Generation - using the LLM to generate code completions based on the prompt and context provided.
-
Post-processing - refining and filtering the raw AI-generated completions to deliver the most relevant suggestions.
The goal of Cody is to provide high-quality completions that integrate seamlessly into a developer's workflow. Creating an effective code AI assistant requires the right context, prompt, and LLM. Through syntactic analysis, smart prompt engineering, proper LLM selection, and the right telemetry we are continuously iterating and improving code completion quality and acceptance rate for Cody. Latest numbers show Cody completion acceptance rate to be as high as 30%.
Curious to see Cody in action for yourself? Get started for free today.